Kecerdasan Artifisial
Pertemuan 05
Pencarian Adversarial - Game Playing
Mata Kuliah: Kecerdasan Artifisial (AI401) | 3 SKS
🎯 Capaian Pembelajaran
Setelah pertemuan ini, mahasiswa mampu:
- Memformulasikan game sebagai problem pencarian adversarial
- Membangun dan menganalisis game tree
- Mengimplementasikan algoritma Minimax
- Menganalisis kompleksitas Minimax O(bm)
- Menerapkan Alpha-Beta Pruning untuk optimasi
- Merancang fungsi evaluasi untuk game
📋 Agenda Hari Ini
Bagian 1
- Pencarian Adversarial
- Karakteristik Game
- Game Tree
- Algoritma Minimax
Bagian 2
- Fungsi Evaluasi
- Alpha-Beta Pruning
- Expectiminimax
- Aplikasi Pertahanan
🔄 Review: Pencarian Sebelumnya
| Pertemuan | Topik | Karakteristik |
|---|---|---|
| 2 | Uninformed Search | Agen tunggal, tanpa heuristik |
| 3 | Informed Search | Agen tunggal, dengan heuristik |
| 4 | Local Search | Agen tunggal, optimasi |
| 5 | Adversarial Search | Multi-agen kompetitif |
🎮 Apa itu Pencarian Adversarial?
Perbedaan utama:
- 🎯 Bukan mencari path ke goal
- ⚔️ Melawan lawan yang juga optimal
- 🔄 Giliran bergantian
📊 Single Agent vs Adversarial
Single Agent (A*)
- Kontrol penuh atas aksi
- Path cost deterministik
- Goal state jelas
Adversarial (Minimax)
- Giliran bergantian
- Lawan memilih optimal
- Mengalahkan lawan
⚠️ A* tidak bisa digunakan langsung untuk game karena lawan akan menghalangi!
🌍 Aplikasi Pencarian Adversarial
🎲 Dalam Game
- Catur, Go, Checkers
- Video game AI
- Card games
🎖️ Konteks Pertahanan
- War gaming & simulasi
- Cyber attack-defense
- Alokasi sumber daya
📂 Klasifikasi Game
Gambar 2.1: Klasifikasi game berdasarkan karakteristiknya
🎲 Deterministik vs Stokastik
Deterministik
State berikutnya pasti ditentukan oleh aksi
Contoh: Catur, Go, Tic-Tac-Toe
Stokastik
Ada elemen keacakan (dadu, kartu)
Contoh: Backgammon, Poker
👁️ Perfect vs Imperfect Information
Perfect Information
Semua pemain melihat seluruh state
Contoh: Catur (semua bidak terlihat)
Imperfect Information
Sebagian informasi tersembunyi
Contoh: Poker (kartu lawan tidak terlihat)
⚖️ Zero-Sum Game
UMAX(s) + UMIN(s) = 0
atau: UMAX(s) = -UMIN(s)
💡 Keuntungan MAX = Kerugian MIN, dan sebaliknya!
♟️ Contoh Zero-Sum: Catur
| Hasil | U(White/MAX) | U(Black/MIN) | Total |
|---|---|---|---|
| White menang | +1 | -1 | 0 ✓ |
| Draw | 0 | 0 | 0 ✓ |
| Black menang | -1 | +1 | 0 ✓ |
🎯 Fokus Pertemuan Ini
Game dengan karakteristik:
- Two-player - Dua pemain bergantian
- Zero-sum - Keuntungan satu = kerugian lainnya
- Perfect information - Semua state terlihat
- Deterministic - Tidak ada keacakan
Contoh: Catur, Tic-Tac-Toe, Connect Four, Checkers
🌳 Game Tree
🏗️ Komponen Game Tree
| Komponen | Deskripsi |
|---|---|
| Root Node | State awal permainan |
| MAX Nodes | Giliran kita (memaksimalkan) |
| MIN Nodes | Giliran lawan (meminimalkan) |
| Terminal Nodes | State akhir dengan nilai utility |
| Branching Factor (b) | Rata-rata langkah legal per state |
| Depth (m) | Kedalaman maksimum tree |
❌⭕ Game Tree: Tic-Tac-Toe
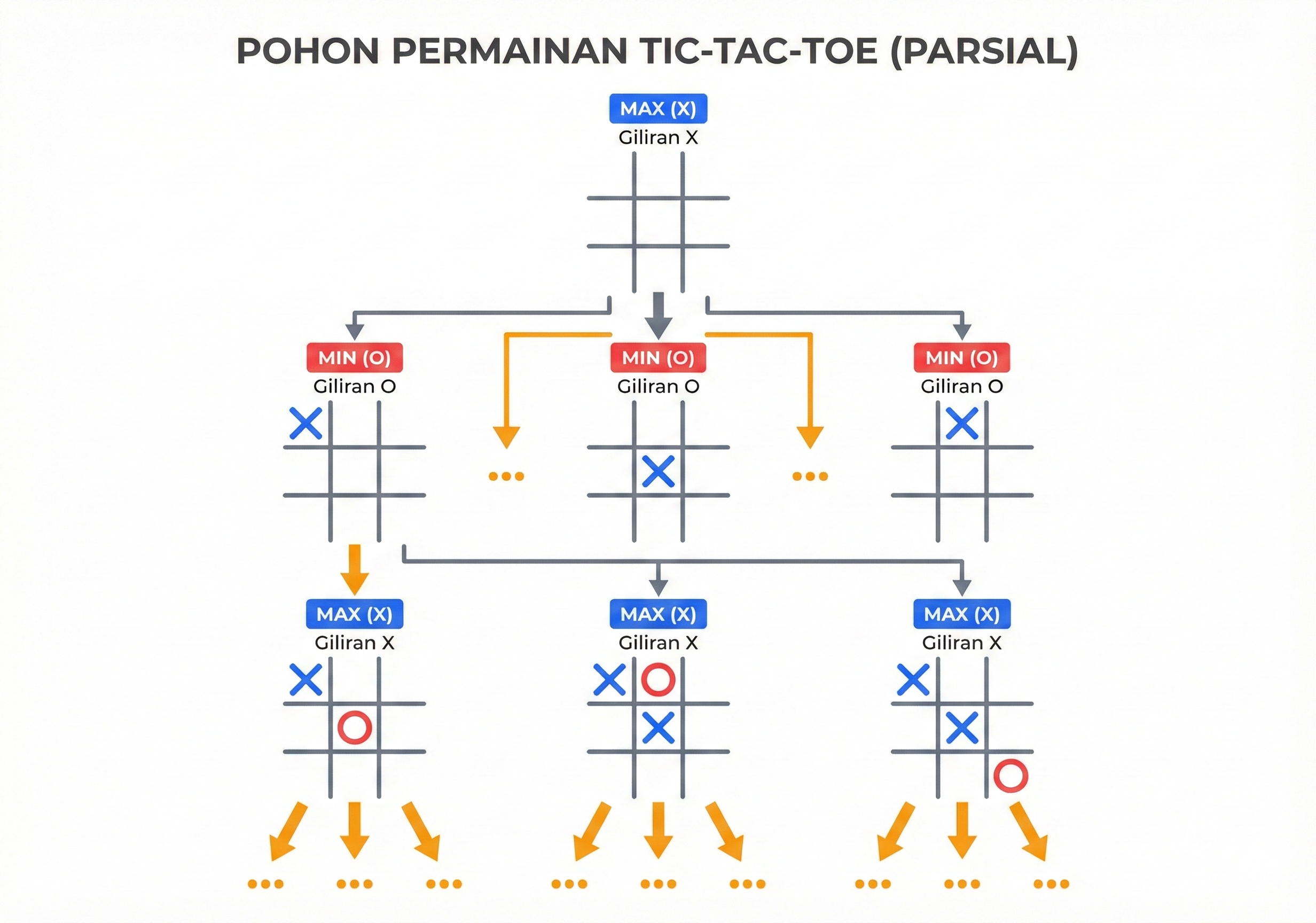
Gambar 3.2: Sebagian game tree untuk Tic-Tac-Toe
📊 Kompleksitas Tic-Tac-Toe
- Branching factor rata-rata: b ≈ 5
- Kedalaman maksimum: m = 9
- Estimasi nodes: 59 ≈ 2 juta
- Actual unique games: ~255,168
💡 Tic-Tac-Toe cukup kecil untuk dieksplorasi sepenuhnya!
🎯 Algoritma Minimax
Prinsip:
- MAX berusaha memaksimalkan nilai
- MIN berusaha meminimalkan nilai
📈 Ilustrasi Minimax
Gambar 4.1: Propagasi nilai dari terminal ke root
📐 Definisi Formal Minimax
MINIMAX(n) =
- Utility(n) jika n terminal
- maxa MINIMAX(Result(n,a)) jika Player(n) = MAX
- mina MINIMAX(Result(n,a)) jika Player(n) = MIN
💻 Pseudocode Minimax
def max_value(state):
if terminal_test(state):
return utility(state)
v = -infinity
for action in actions(state):
v = max(v, min_value(result(state, action)))
return v
def min_value(state):
if terminal_test(state):
return utility(state)
v = +infinity
for action in actions(state):
v = min(v, max_value(result(state, action)))
return v
✏️ Contoh: Hitung Minimax
A (MAX)
/|\
/ | \
B C D (MIN)
/\ | /\
3 5 2 6 1
Step 1: MIN nodes
- B = min(3, 5) = 3
- C = 2
- D = min(6, 1) = 1
Step 2: MAX node
A = max(3, 2, 1) = 3 → Pilih B!
⏱️ Kompleksitas Minimax
Time Complexity: O(bm)
Space Complexity: O(bm)
| Game | b | m | Nodes |
|---|---|---|---|
| Tic-Tac-Toe | ~5 | 9 | ~106 |
| Chess | ~35 | ~100 | ~10154 😱 |
| Go | ~250 | ~150 | ~10360 🤯 |
📊 Fungsi Evaluasi
✅ Properti Fungsi Evaluasi yang Baik
- Konsisten dengan utility - Setuju untuk terminal states
- Cepat dihitung - Tidak terlalu kompleks
- Reflektif - Nilai tinggi = peluang menang tinggi
- Linear combination - Weighted sum dari features
♟️ Contoh: Evaluasi Catur
Eval(s) = w₁·material + w₂·mobility + w₃·king_safety + ...
| Piece | Value |
|---|---|
| Pawn | 1 |
| Knight/Bishop | 3 |
| Rook | 5 |
| Queen | 9 |
Material advantage adalah feature paling penting!
✂️ Mengapa Perlu Pruning?
Minimax mengevaluasi banyak node yang tidak perlu!
Contoh: Catur dengan depth 4
354 = 1.5 juta nodes
Dengan Alpha-Beta optimal:
352 = 1,225 nodes (99.9% lebih sedikit!)
🔪 Alpha-Beta Pruning
α (Alpha)
Nilai minimum yang dijamin MAX
(lower bound)
β (Beta)
Nilai maksimum yang dijamin MIN
(upper bound)
📊 Ilustrasi Alpha-Beta
Gambar 6.1: Pruning terjadi ketika α ≥ β
⚡ Kondisi Pruning
Pada MIN node
Jika nilai ≤ α
→ Prune!
(MAX tidak akan pilih path ini)
Pada MAX node
Jika nilai ≥ β
→ Prune!
(MIN tidak akan pilih path ini)
Pruning Rule: α ≥ β → PRUNE!
💻 Pseudocode Alpha-Beta
def max_value(state, alpha, beta):
if terminal_test(state): return utility(state)
v = -infinity
for action in actions(state):
v = max(v, min_value(result(state, action), alpha, beta))
if v >= beta: return v # Prune!
alpha = max(alpha, v)
return v
def min_value(state, alpha, beta):
if terminal_test(state): return utility(state)
v = +infinity
for action in actions(state):
v = min(v, max_value(result(state, action), alpha, beta))
if v <= alpha: return v # Prune!
beta = min(beta, v)
return v
✏️ Contoh Alpha-Beta Pruning
A (MAX)
/ | \
B C D (MIN)
/\ /\ /\
3 5 6 2 1 8
- B = min(3,5) = 3 → α = 3
- C: cek 6, lalu 2. min = 2 (tidak dipilih, 2 < 3)
- D: cek 1. 1 ≤ α(3)? Ya! → PRUNE 8! ✂️
- A = max(3, 2, 1) = 3
Node 8 tidak perlu dievaluasi!
📊 Efisiensi Alpha-Beta
| Kondisi | Kompleksitas | Penjelasan |
|---|---|---|
| Worst case | O(bm) | Tidak ada pruning |
| Random order | O(b3m/4) | Pruning moderat |
| Perfect order | O(bm/2) | Pruning optimal! |
🎯 Perfect ordering = kedalaman pencarian 2x lipat!
📋 Teknik Move Ordering
Untuk mendekati efisiensi optimal:
- Killer Move Heuristic - Simpan langkah yang menyebabkan cutoff
- History Heuristic - Lacak langkah yang sering sukses
- Iterative Deepening - Gunakan hasil pencarian dangkal
- Transposition Table - Cache hasil evaluasi
🎲 Expectiminimax
🎯 Chance Nodes
Pada chance node, hitung expected value:
E[V] = Σ P(r) × MINIMAX(Result(n, r))
⚠️ Kelemahan:
Alpha-Beta kurang efektif karena chance nodes memerlukan semua children!
🎖️ Aplikasi: Simulasi Pertahanan
Skenario: Defender vs Attacker dalam pertahanan pulau
- Defender (MAX): Memilih posisi unit pertahanan
- Attacker (MIN): Memilih jalur serangan
- Utility: +1 jika pertahanan berhasil, -1 jika gagal
Minimax membantu menemukan strategi pertahanan optimal!
🔐 Aplikasi: Cyber Defense
Defender:
- Pilih sistem untuk diperkuat
- Alokasi sumber daya keamanan
Attacker:
- Pilih target serangan
- Memaksimalkan damage
💡 Minimax memprediksi serangan rasional untuk proactive defense!
🧠 Quiz Time!
Pertanyaan 1:
Dalam zero-sum game, jika MAX mendapat utility +5, berapa utility MIN?
💡 Zero-sum: UMAX + UMIN = 0
🧠 Quiz Time!
Pertanyaan 2:
Kapan Alpha-Beta Pruning melakukan pruning pada MIN node?
🧠 Quiz Time!
Pertanyaan 3:
Game Backgammon termasuk kategori:
💡 Ada dadu (stokastik), tapi semua bidak terlihat (perfect info)
📝 Ringkasan
| Konsep | Poin Kunci |
|---|---|
| Adversarial Search | Pencarian dengan lawan kompetitif |
| Zero-Sum | UMAX + UMIN = 0 |
| Minimax | MAX maximizes, MIN minimizes |
| Kompleksitas | O(bm) tanpa pruning |
| Alpha-Beta | O(bm/2) dengan perfect ordering |
| Expectiminimax | Untuk game dengan keacakan |
📅 Pertemuan Berikutnya
Pertemuan 06: Constraint Satisfaction Problems
CSP dan Teknik Penyelesaiannya
- Formulasi CSP: variabel, domain, constraint
- Constraint Propagation (AC-3)
- Backtracking Search dengan heuristik
- Contoh: Map Coloring, Sudoku
📚 Referensi
- Russell, S. & Norvig, P. (2020). Artificial Intelligence: A Modern Approach (4th Ed.). Pearson. Chapter 5: Adversarial Search
- Ertel, W. (2017). Introduction to Artificial Intelligence (2nd Ed.). Springer. Chapter 6.
- CS188 Berkeley AI Materials: https://inst.eecs.berkeley.edu/~cs188/
Terima Kasih
🤖 Kecerdasan Artifisial
Pertemuan 05: Pencarian Adversarial - Game Playing
Ada pertanyaan?